综合评分
核心要点
文章结构大纲
1. 引言: 用 Agent 构建工具
2. 第一步: 快速原型
3. 第二步: 建立评估
4. 第三步: Agent 协作优化
5. 工具选择原则
6. Namespacing 命名空间
7. 返回有意义的上下文
8. Prompt-engineer 工具描述
深度解读 苏格拉底式深度解读 →
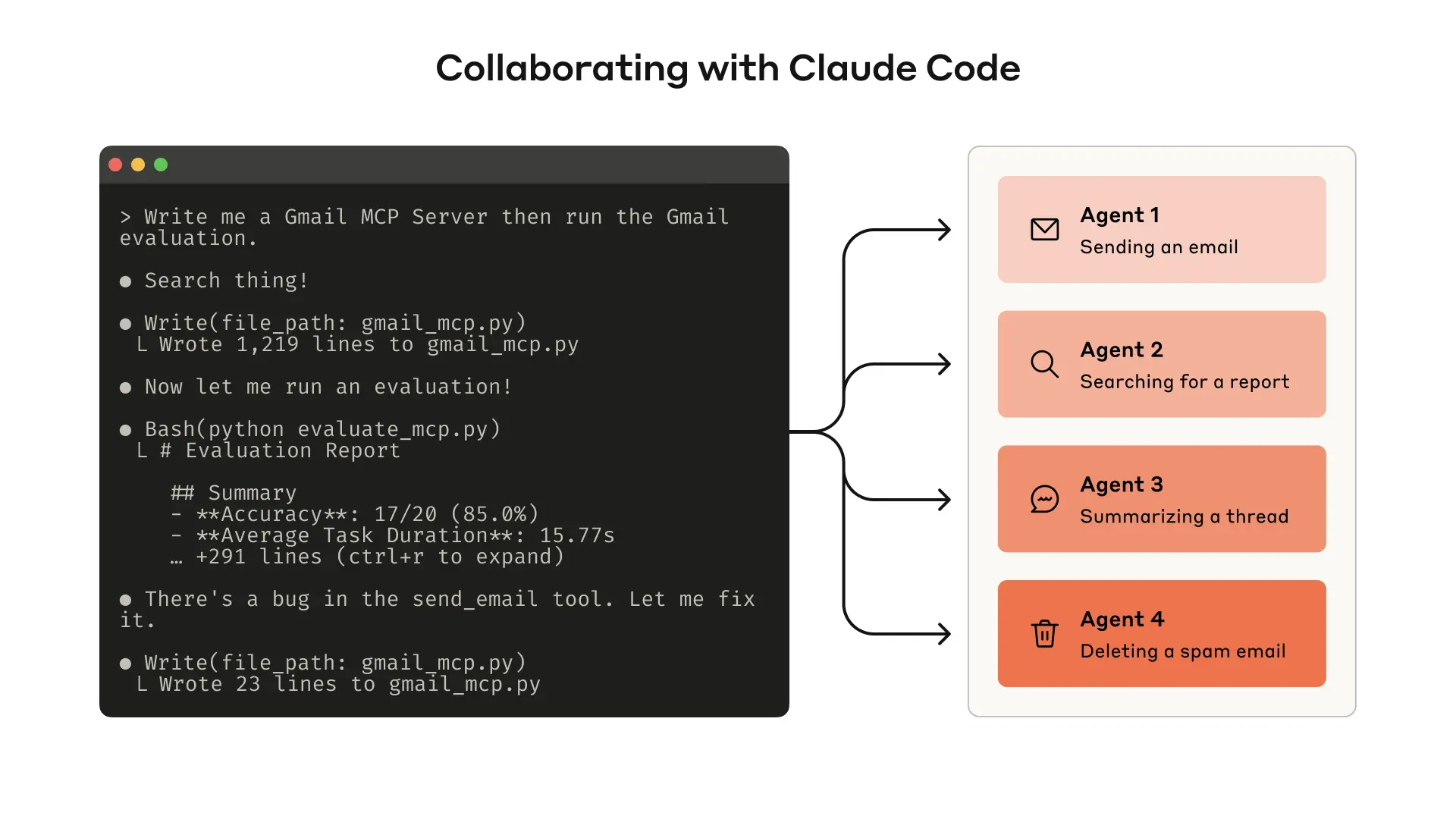
这是一个巧妙的元策略 — 用 Agent 来构建给 Agent 使用的工具:
工作流程:
- 用自然语言描述工具需求("我需要一个搜索 GitHub 仓库的工具")
- Claude Code 生成完整的 MCP Server 代码(包括 schema 定义、错误处理、类型注解)
- 测试工具,观察 Agent 在真实场景中的表现
- 根据观察结果修改工具描述和参数
为什么这比手写更高效:
- Claude Code 熟悉 MCP 协议的规范和最佳实践
- 生成的代码天然遵循一致的 schema 格式
- 可以在几分钟内迭代多个版本
局限: 自动生成的工具在复杂场景(如需要状态管理、事务处理)下可能不够精确。但作为初始原型,快速验证"这个工具是否有价值"远比精心设计一个没用的工具重要。
这个原则直接源于上下文管理的考量:
多工具的问题:
- 每个工具的定义占用 200-500 tokens(见 Advanced Tool Use 分析)
- 100 个工具 = 20-50K tokens 仅用于定义
- 工具越多,模型选择正确的工具越困难(选择准确率随工具数增加而下降)
少而精的策略:
- 将相关的 API 操作合并到一个工具中(如: 用
manage_issue替代create_issue+update_issue+close_issue) - 通过参数区分行为(action: create/update/close)
- 只为"高影响工作流"构建工具 — 即 Agent 真正常用的操作链
判断标准: 如果两个工具总是在同一工作流中被连续调用,考虑合并它们。如果一个工具只在 < 5% 的场景中被使用,考虑删除它(或标记为 defer_loading)。
返回值设计是 ACI 中最容易被忽视的部分:
反模式: 返回原始数据
{"id": "usr_8x7k2m", "status": "active", "org_id": "org_3n5p9q"}
- LLM 看到 "usr_8x7k2m" 无法知道这是谁
- 需要额外调用获取用户名和组织名
- 浪费 tokens 和 API 调用
推荐: 返回有意义的上下文
{"name": "Alice Chen", "email": "alice@example.com", "org": "Engineering", "status": "active"}
- LLM 可以直接向用户展示结果
- 可以基于组织名做出后续决策
- 减少 2-3 次额外的工具调用
Token 效率平衡: 返回更多上下文会增加每次工具调用的 token 成本,但减少了总调用次数。在大多数场景下,"一次返回足够信息" 比 "多次返回最少信息" 的总成本更低。
工具描述是 ACI 中投入产出比最高的优化点:
新员工类比为什么有效:
- 新员工没有领域知识 → 工具描述需要解释"为什么",不只是"做什么"
- 新员工需要示例才能理解惯例 → 提供 input_examples
- 新员工会在边界情况下犯错 → 明确说明错误处理和边界
描述的三个层次:
- 目的层: "搜索指定目录下的文件内容"
- 行为层: "支持正则表达式和 glob 模式。返回匹配行的上下文(前后各 2 行)。限制最多返回 50 个匹配。"
- 指导层: "对于大型代码库,建议先用 list_files 缩小范围再用此工具搜索。"
实测效果: 在 Claude Code 内部测试中,优化工具描述后:
- 工具选择准确率从 ~75% 提升到 ~92%
- 参数错误率从 ~30% 降至 ~8%
- 与 Advanced Tool Use 中的 Tool Use Examples 数据一致(72% → 90%)
这是一个令人意外的发现: 格式选择不只是审美偏好,而是有可量化的性能影响:
实测数据(Claude Code 内部):
- XML: 结构清晰,模型最容易正确解析。适合层级嵌套数据。
- JSON: 紧凑,适合键值对。但在复杂嵌套时不如 XML 直观。
- Markdown: 适合自由文本。但在需要精确解析时不够可靠。
选择建议:
- 结构化数据(列表、嵌套对象)→ XML 或 JSON
- 自由文本(解释、建议)→ Markdown
- 混合内容(结构 + 文本)→ XML(用标签包裹文本块)
深层原因: 模型在训练数据中见到的 XML 标签通常是结构清晰的,而 JSON 的嵌套关系在 token 化后可能不那么直观。格式选择直接影响模型的"解析成功率"。
关联 GitHub 项目
claude-cookbooks43500 stars代码实践建议
用 Claude Code 构建一个 MCP Server
选择一个常用 API(如 GitHub/Slack),让 Claude Code 生成 MCP Server 原型,然后测试和优化
建立工具评估框架
创建评估任务集(prompt-response pairs),用 LLM-as-judge 自动评分,追踪工具修改的性能变化
优化现有工具的 Token 效率
为工具添加 response_format 参数(concise/detailed),对比两种模式下的 token 消耗和准确率
思维流程导图
flowchart TD A["Writing Effective Tools"] --> B["开发流程"] A --> C["设计原则"] B --> B1["1. 快速原型
Claude Code 一次性生成"] B --> B2["2. 建立评估
真实任务 + LLM Judge"] B --> B3["3. 协作优化
Agent 分析结果并改写"] C --> C1["工具选择
少而精,合并功能"] C --> C2["命名空间
前缀/后缀分组"] C --> C3["返回值
高信号,自然语言"] C --> C4["Token 效率
分页+截断+过滤"] C --> C5["描述工程
像写新人文档"]
这个论点揭示了 Agent 系统的一个根本性转变:
传统软件: API 是开发者之间的契约
Agent 系统: 工具是 LLM 与外部系统的契约
为什么这是新契约: LLM 不像人类开发者那样可以"猜测"接口行为。如果工具返回一个 UUID,人类开发者知道去查数据库;但 LLM 可能直接把 UUID 展示给用户。如果错误信息是 "Error 500",人类开发者知道是服务端问题;LLM 可能重试同样的请求。