Writing Effective Tools for AI Agents — with Agents
解读目录
1. 工具即新契约 — 文章核心论点 2. 用 Agent 构建 Agent 工具的元循环 3. 工具选择原则: 少而精 4. 返回值设计: 为推理优化而非为存储优化 5. 工具描述工程学 6. 响应格式的非平凡影响Tools are the new contract between deterministic and non-deterministic systems. They need to be designed for agents, not for developers.
想象你开了一家餐厅,以前菜单是写给厨师的——他们知道"焯水"是什么意思。现在菜单要写给一台烹饪机器人,它不知道"焯水"是什么,你得写"将食材放入 100°C 沸水中浸泡 30 秒后捞出"。工具就是这张新菜单:它不是给人看的菜谱,而是给机器人看的精确操作手册。
flowchart LR
subgraph 传统模式
H[人类开发者] -->|读文档| API[REST API]
API -->|返回原始数据| H
H -->|靠经验补全| D[决策]
end
subgraph Agent模式
A[LLM Agent] -->|读schema| T[Agent工具]
T -->|返回丰富上下文| A
A -->|直接推理| D2[决策]
end
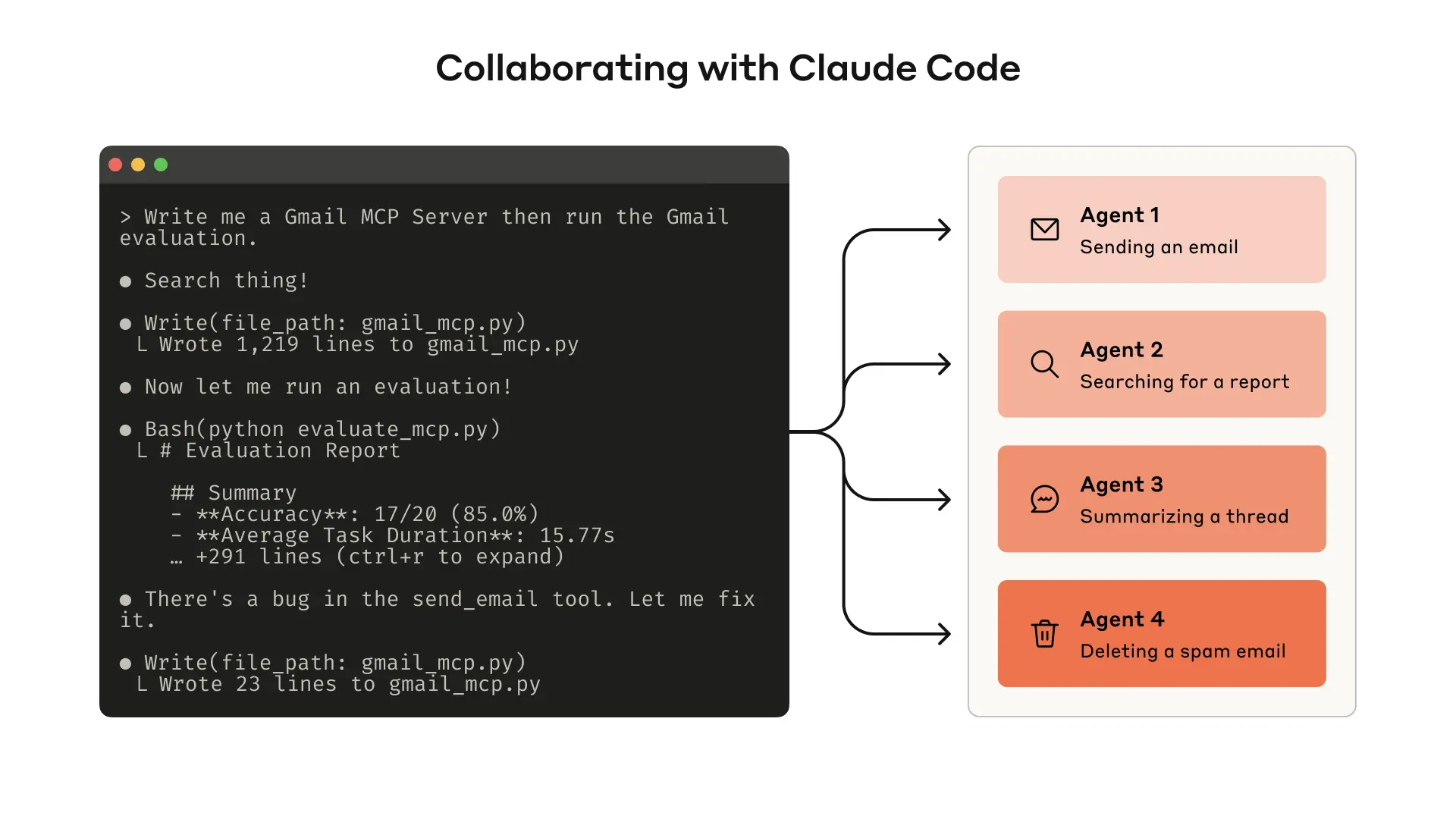
Start by building a quick prototype with Claude Code. Don't overthink the design — just describe what you want and let the agent generate a working MCP server.
这就像让一个厨师帮你设计厨房。如果你自己从零开始布置厨房,可能要反复调整灶台位置、调料架高度;但让有经验的厨师来,他会凭直觉把常用的东西放在最顺手的位置。Claude Code 就是那个"有经验的厨师"——它用过无数次 MCP 工具,知道工具应该长什么样。
flowchart TD
A[自然语言描述需求] --> B[Claude Code 生成 MCP Server]
B --> C{测试工具}
C -->|表现不佳| D[Agent 分析失败原因]
D --> E[自动改写描述/参数]
E --> C
C -->|表现良好| F[发布工具]
B -.->|包含| B1[Schema 定义]
B -.->|包含| B2[错误处理]
B -.->|包含| B3[类型注解]
Fewer, more capable tools often outperform many narrow tools. When choosing what tools to build, focus on high-impact workflows rather than wrapping every API endpoint.
想象你的工具箱里有 100 把螺丝刀,每把只能拧一种螺丝。你每次要花很长时间找到对的那把。但如果只有 5 把多功能螺丝刀,每把能拧多种螺丝,你的效率会高得多。Agent 面对工具选择也是一样——工具越多,选择越慢,选错的概率也越高。
flowchart TD
subgraph 反模式: 工具爆炸
T1[create_issue]
T2[update_issue]
T3[close_issue]
T4[delete_issue]
T5[get_issue]
T6[list_issues]
end
subgraph 推荐: 少而精
M1["manage_issue
(action: create/update/close)"]
M2["search_issues
(query + filters)"]
end
T1 -.->|合并| M1
T2 -.->|合并| M1
T3 -.->|合并| M1
T5 -.->|合并| M2
T6 -.->|合并| M2
Return natural language names instead of UUIDs. Return the context needed for the next step, not just the raw data. The agent needs to reason about the results.
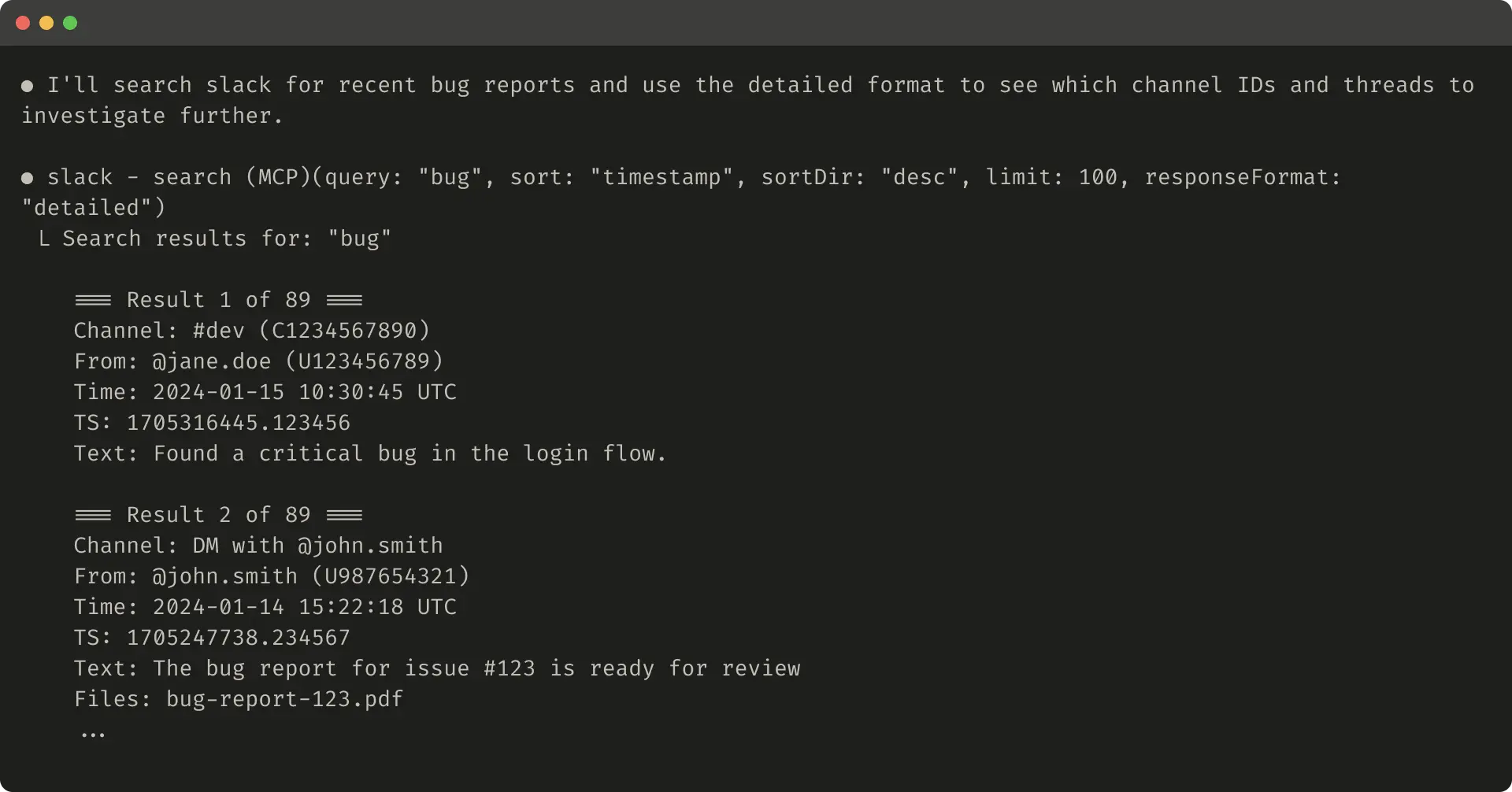
你去问路,如果对方只说"往东走 200 米"然后挂了电话,你到了之后还得再打电话问。但如果对方一次说清楚"往东走 200 米,到了红绿灯左转,看到蓝色大楼就是",你就不用再打扰他了。工具返回值也是一样——一次给够信息,比让 Agent 反复追问效率高得多。
flowchart TD
subgraph 反模式: 最小返回
R1["{id: usr_8x7k2m}"] --> A1[Agent 需要更多上下文]
A1 --> C1[再调用 getUserById]
C1 --> A2[Agent 需要组织名]
A2 --> C2[再调用 getOrgById]
C2 --> A3[终于能回答用户]
end
subgraph 推荐: 自包含返回
R2["{name: Alice Chen,
org: Engineering,
team: Backend}"] --> A4[Agent 直接回答用户]
end
Write tool descriptions like onboarding documentation for a new employee. Explain the purpose, provide examples, and clarify edge cases.
想象你招了一个能力很强但完全不了解公司业务的新员工。如果你只告诉他"处理客户请求",他会手足无措。但如果你写了一份详尽的手册——什么时候做什么、遇到异常怎么处理、哪些事绝对不能做——他就能快速上手。工具描述就是给 Agent 写的"新员工手册"。
flowchart TD A["工具描述"] --> B["目的层
这个工具是做什么的"] A --> C["行为层
具体怎么用、支持什么"] A --> D["指导层
什么时候用/不用"] B --> B1["例: 搜索指定目录下的文件内容"] C --> C1["例: 支持正则和glob,返回匹配行上下文"] D --> D1["例: 大型代码库建议先list_files缩小范围"] style B fill:#e8f5e9 style C fill:#fff3e0 style D fill:#e3f2fd
Response format matters more than you'd think. XML, JSON, and Markdown each have measurably different performance impacts on how well the agent uses the results.
就像同一条信息,写在便利贴上和写在正式信纸上,给人的感觉完全不同。XML 像是分类整理好的文件夹——每个标签都清楚地标明了内容类型;JSON 像是密密麻麻的表格——紧凑但需要仔细辨别字段关系;Markdown 像是手写笔记——灵活自由,但不太适合精确的结构化数据。
flowchart TD
D{数据类型} -->|层级嵌套| XML["XML 格式
<user><name>Alice</name>
<org>Engineering</org></user>"]
D -->|简单键值对| JSON["JSON 格式
{name: Alice, org: Engineering}"]
D -->|自由文本| MD["Markdown 格式
# 用户信息
- 姓名: Alice
- 部门: Engineering"]
XML --> P1["解析错误率最低
Token 消耗较高"]
JSON --> P2["紧凑高效
深层嵌套时易混淆"]
MD --> P3["灵活自由
结构化解析不够可靠"]