Introducing Advanced Tool Use on the Claude Developer Platform
苏格拉底式深度解读
解读目录
1. 工具定义膨胀问题 — Tool Search Tool 的动机 2. Programmatic Tool Calling 的核心机制 3. Tool Use Examples 的效果数据 4. 组合策略的实施路径1工具定义膨胀问题 — Tool Search Tool 的动机
原文摘录
When you have dozens or hundreds of tools, the tool definitions alone can consume tens of thousands of tokens — crowding out the actual context the model needs to reason about the task.
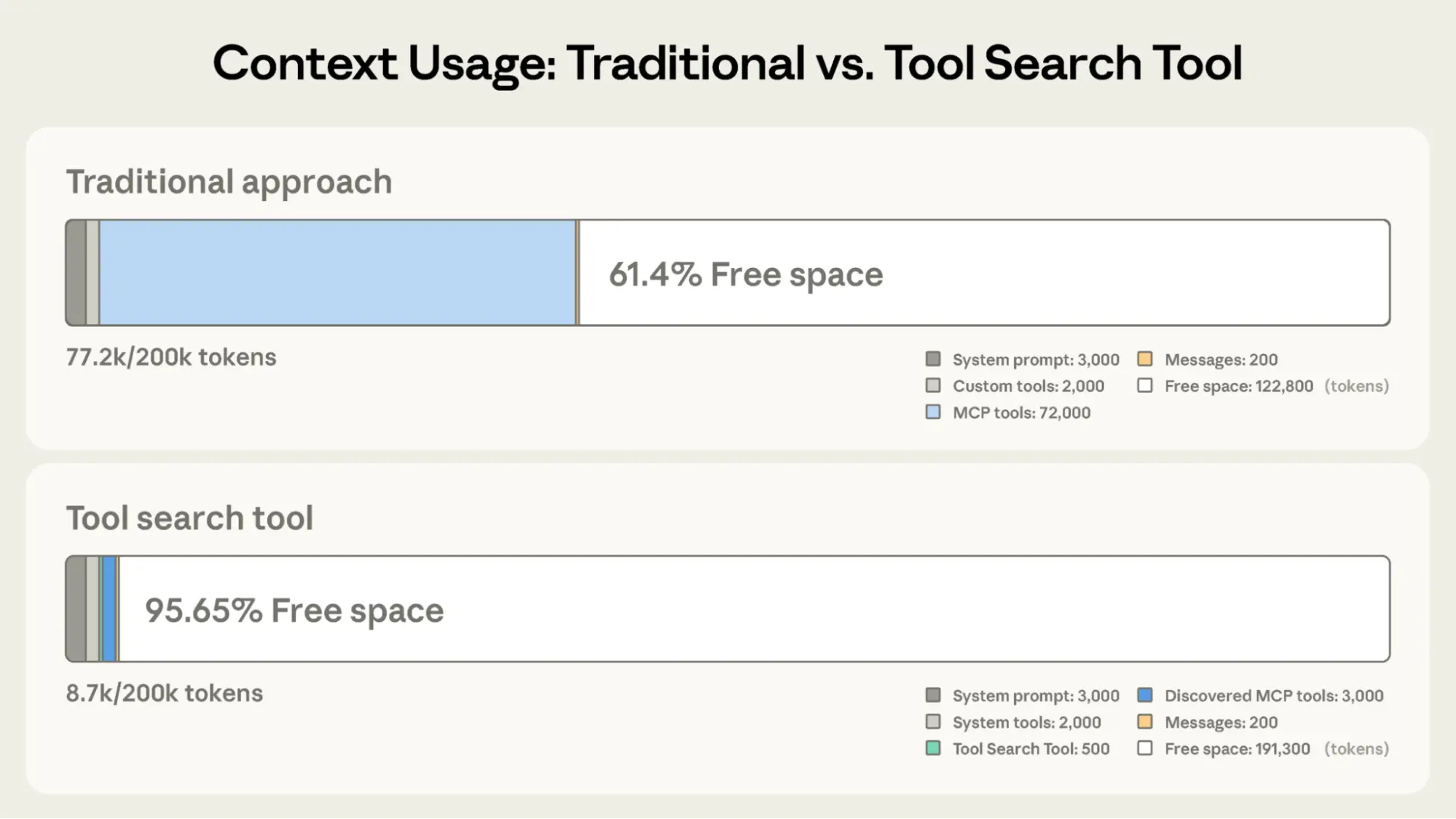
Tool Search Tool — 按需发现和加载工具定义,减少 85% 上下文占用
💡 类比理解
想象你去图书馆查资料 -- 老办法是把整个书架搬到你桌上(预加载所有工具定义),新办法是先查目录卡(Tool Search),找到需要的书再拿过来(按需加载)。桌上只放正在用的书,省下大量桌面空间留给真正的思考。
为什么工具定义多了反而影响 Agent 能力?
因为每个工具的 JSON Schema 占 200-500 tokens,100 个工具就吃掉 20K-50K tokens。模型的上下文窗口是有限的,工具定义越多,留给任务推理的空间越少,相当于'手册越厚越找不到重点'。
Tool Search Tool 具体怎么实现按需加载?
核心是两步: (1) 所有工具标记 defer_loading: true,定义不随请求发送;(2) 系统注入一个特殊的 tool_search 工具,Agent 先用它搜索发现相关工具,再由系统动态加载对应定义。
搜索策略(regex/BM25/embedding)怎么选择?各有什么权衡?
regex 精确但只能匹配工具名称字面量;BM25 基于词频统计,适合中等规模工具集;embedding 支持语义匹配,能理解'搜索文件'和'查找文档'是同一类需求,但需要额外的向量索引构建成本。实际中可组合使用: 先 regex 快速匹配,未命中再用 BM25/embedding 兜底。
85% 的 token 节省会不会以降低准确率为代价?实测数据怎么说?
实测中 Opus 4 的准确率反而从 49% 提升到 74%。原因是减少了无关工具的干扰 -- 模型只需在少量高相关工具中选择,降低了'选错工具'的概率。这验证了 Less Context, Better Performance 的反直觉结论。
📊 原理图解
flowchart LR
subgraph 传统方式
A1["所有工具定义
72K tokens"] --> A2["塞满上下文"]
A2 --> A3["推理空间不足"]
end
subgraph Tool Search Tool
B1["defer_loading: true"] --> B2["tool_search 搜索"]
B2 --> B3["BM25/Embedding 匹配"]
B3 --> B4["按需加载
8.7K tokens"]
B4 --> B5["85% token 节省
准确率 49%→74%"]
end
Tool Search Tool 工作流程: 从预加载全部工具定义到按需搜索加载,上下文从 72K 降至 8.7K tokens
claude-agent-sdk-python
SDK 中实现了 Tool Search Tool 的 defer_loading 和 tool_search 机制
claude-code
Claude Code CLI 中大量工具采用 ToolSearch 按需加载策略
2Programmatic Tool Calling 的核心机制
原文摘录
Instead of the model calling tools one at a time through the standard tool use loop, programmatic tool calling lets the model write Python code that orchestrates multiple tool calls — with loops, conditionals, and error handling.
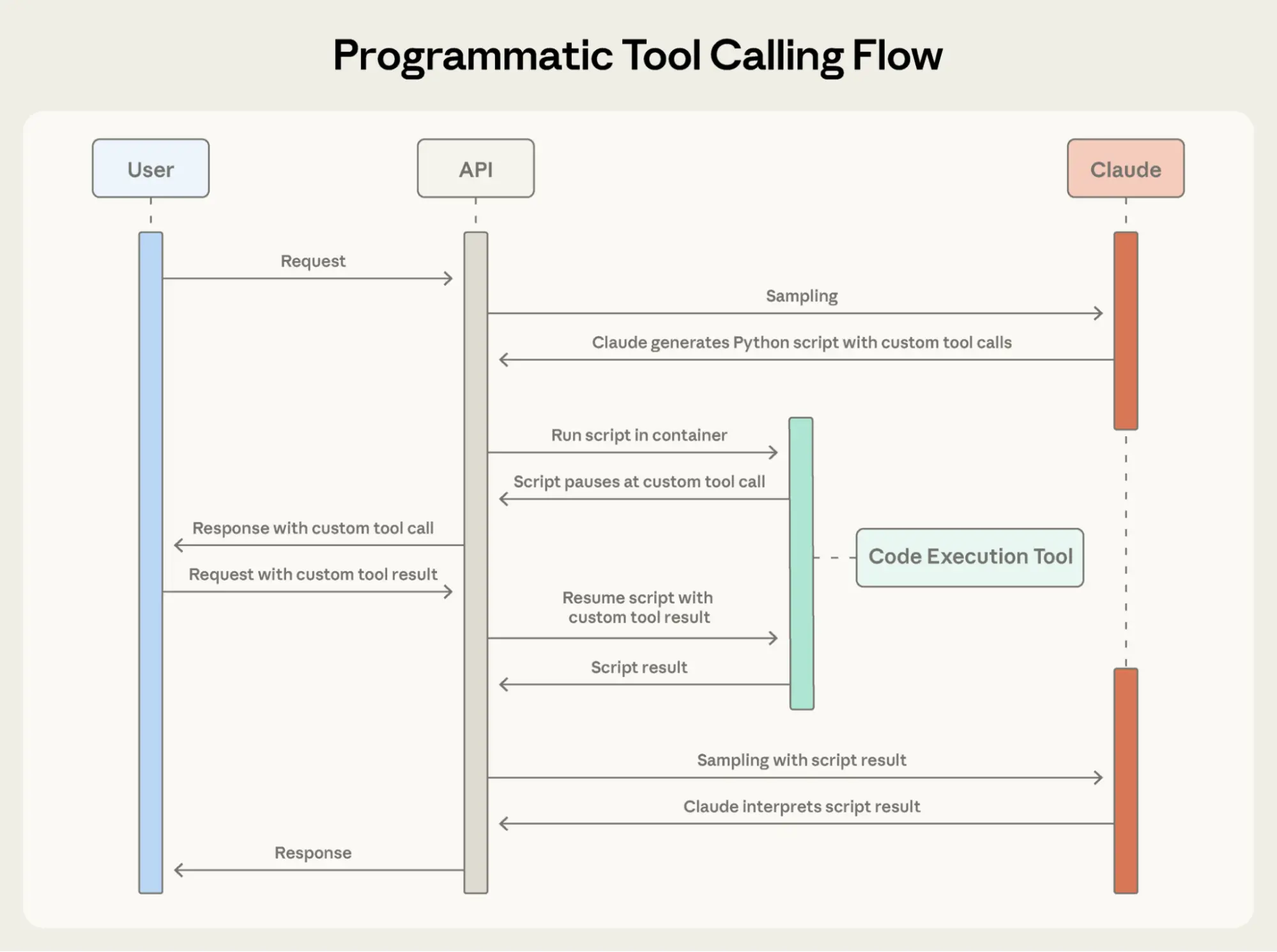
Programmatic Tool Calling — Agent 编写 Python 代码编排多步骤工具调用
💡 类比理解
传统工具调用像你在微信群里指挥同事干活 -- 说一句做一句,每句对话都留在聊天记录里(上下文)。Programmatic Tool Calling 像你写了一份脚本交给同事执行 -- 同事自己跑完所有步骤,最后只给你一份总结报告,聊天记录里只有一句话。
传统工具调用和 Programmatic Tool Calling 有什么本质区别?
传统方式是一问一答式: Agent 调用工具 → 结果返回对话 → 再调用下一个。每一步中间结果都占用上下文。Programmatic 方式是 Agent 写一段 Python 代码,代码里直接调用多个工具,中间变量存在 Python 运行时,不进入对话上下文。
为什么中间结果不进入上下文这么重要?
因为处理大数据集时,中间结果可能非常庞大。比如处理 200KB 数据,传统方式会把 200KB 的中间数据全部塞进上下文,很快就会撑爆上下文窗口。Programmatic 方式只在上下文中保留 Agent 指定的最终摘要(可能只有 1KB),token 减少 37%。
Python 代码中的 for/while/if 是怎么和工具调用交互的?
Agent 在 Python 代码中使用特殊语法直接引用工具,比如 tools.search(query='error')。SDK 在运行时拦截这些调用,映射到实际的 API 工具。循环、条件、异常处理都是原生 Python 语义,不需要 LLM 多轮推理来模拟控制流。
如果工具调用在代码中抛出异常,Agent 怎么处理?
因为代码运行在沙箱环境中,Agent 可以用标准 try/except 捕获异常,决定重试、跳过或记录错误。这比传统方式(依赖 LLM 判断错误信息然后决定下一步)更可靠,因为错误处理逻辑是确定性代码而非概率性推理。
📊 原理图解
flowchart TD
subgraph 传统工具调用
A1["Agent: 调用工具A"] --> A2["结果进上下文"]
A2 --> A3["Agent: 调用工具B"]
A3 --> A4["结果进上下文"]
A4 --> A5["Agent: 调用工具C"]
A5 --> A6["结果进上下文
200KB 中间数据"]
end
subgraph Programmatic Tool Calling
B1["Agent: 写 Python 代码"] --> B2["代码中调用工具A/B/C"]
B2 --> B3["Python 运行时处理
中间变量不进上下文"]
B3 --> B4["只返回 1KB 摘要
Token 减少 37%"]
end
Programmatic Tool Calling: Agent 编写 Python 代码编排多步工具调用,中间结果不污染对话上下文
claude-agent-sdk-python
SDK 中提供 Programmatic Tool Calling 的 Python 沙箱和工具编排接口
claude-code
Claude Code 内部使用 code execution 编排复杂工具调用链
3Tool Use Examples 的效果数据
原文摘录
Adding just a few concrete input examples to your tool definitions improved tool use accuracy from 72% to 90% in our benchmarks.
💡 类比理解
JSON Schema 像字典的词性标注(名词、动词、形容词),告诉你参数的结构和类型。但光看词性标注你不会造句 -- 你需要例句。Tool Use Examples 就是给工具'造例句',让模型一看就懂这个工具在真实场景中该怎么用。
为什么 JSON Schema 定义已经够详细了,还需要加示例?
Schema 定义的是'结构'(类型、约束),但不传达'意图'和'惯例'。比如一个 search 工具的 query 参数,Schema 只说它是字符串,但示例能展示: 用户习惯用自然语言还是关键词、支持不支持布尔运算、特殊字符怎么处理。模型通过 few-shot 学习快速掌握这些隐性规范。
示例应该包含哪些内容才能最大化效果?
三个层次的示例搭配使用效果最好: 完整示例(所有参数填写,展示理想输入)、部分示例(只填必要参数,展示最小可行输入)、边界示例(空值、超长文本、特殊字符等特殊处理)。覆盖这三种场景,准确率提升最显著。
18% 的准确率提升(72%→90%)是怎么测出来的?可靠吗?
这是 Anthropic 官方基准测试数据,基于多种工具调用场景的标准化评测集。18% 的提升在 LLM 评估中属于非常大的增益 -- 作为对比,很多 prompt 优化技巧只能带来 2-3% 的提升。而且这个方法的成本极低,只需在工具定义中加几行 JSON。
示例多了会不会反而干扰模型,或增加不必要的 token 开销?
关键在于示例的典型性而非数量。官方推荐 2-5 个精选示例即可,每个示例大约增加 50-100 tokens。相比 18% 的准确率提升,这点 token 增加微不足道。但要避免示例之间互相矛盾或覆盖过于相似的场景,那样反而会让模型困惑。
📊 原理图解
flowchart LR
subgraph 仅 Schema 定义
A1["JSON Schema
类型+约束"] --> A2["准确率 72%
模型猜测惯例"]
end
subgraph Schema + Examples
B1["JSON Schema"] --> B2["+ 完整示例"]
B2 --> B3["+ 最小参数示例"]
B3 --> B4["+ 边界情况示例"]
B4 --> B5["准确率 90%
+18% 提升"]
end
Tool Use Examples 效果: 仅用 Schema 定义准确率 72%,添加精选示例后提升至 90%
claude-agent-sdk-python
SDK 中的工具定义支持 input_examples 字段,用于添加使用示例
claude-code
Claude Code 的内置工具广泛使用示例来提升模型调用准确率
4组合策略的实施路径
原文摘录
The three features are complementary and can be stacked: first solve your biggest bottleneck, then layer on additional features for compounding gains.
💡 类比理解
三层策略像装修房子的优先级排序: 先修最大的漏水管道(Tool Search Tool,解决 85% 的 token 浪费),再优化电路布线(Programmatic Tool Calling,减少中间数据噪声),最后挂几幅画点缀(Tool Use Examples,提升 18% 准确率)。每层独立有效,叠加效果倍增。
为什么建议'先解决最大瓶颈'而不是三个特性一起上?
因为三个特性解决的问题不同、收益量级也不同。Tool Search Tool 单独就能节省 85% token,是投入产出比最高的。先把最大瓶颈解决,再逐步叠加其他特性,可以逐步验证每个特性的效果,避免'全部上线后不知道哪个在起作用'的困境。
三层叠加后 token 从 72K 降到约 5K,这个计算是怎么来的?
第一层 Tool Search Tool 将工具定义从 72K 降至 8.7K(85% 节省);第二层 Programmatic Tool Calling 进一步减少约 37% 的上下文(中间结果不进入上下文);第三层 Tool Use Examples 增加少量 token(每个示例约 50-100 tokens),但带来 18% 准确率提升。综合下来约 5K tokens。
在实际项目中,三层特性分别适合什么规模的团队和场景?
第一层适合工具数量 > 20 的团队,改造成本低(只需标记 defer_loading 和实现搜索接口)。第二层适合有多步骤编排需求的场景(数据处理、批量操作),需要代码执行环境支持。第三层成本最低(加几行 JSON),所有项目都应该做。小型项目可以直接从第三层开始。
叠加策略有没有什么边界情况或副作用需要注意?
几个注意点: (1) Tool Search Tool 的搜索质量直接决定后续效果,如果搜索不准,加载了错误工具反而降低性能;(2) Programmatic Tool Calling 需要沙箱环境,需评估安全风险;(3) Examples 如果与实际行为不一致,会产生'错误的 confidence',模型自信地做出错误调用。建议每层上线后都做 A/B 测试验证。
📊 原理图解
flowchart TD A["72K tokens
全部工具定义"] --> B["第一层: Tool Search Tool"] B --> B1["8.7K tokens
按需加载
准确率 49%→74%"] B1 --> C["第二层: Programmatic Tool Calling"] C --> C1["~5.5K tokens
中间结果不进上下文
Token 再减 37%"] C1 --> D["第三层: Tool Use Examples"] D --> D1["~5K tokens
+2-5 个示例
准确率 72%→90%"] D1 --> E["综合效果
85%+ token 节省
准确率大幅提升"]
三层叠加策略: 逐层解决瓶颈,从 72K tokens 降至约 5K,同时准确率从 49% 提升至 90%
claude-agent-sdk-python
SDK 完整实现了三层高级工具使用特性的组合方案
claude-code
Claude Code 是三层叠加策略的最佳实践参考: ToolSearch + Code Execution + Examples