综合评分
核心要点
文章结构大纲
1. 引言: RAG 的上下文丢失问题
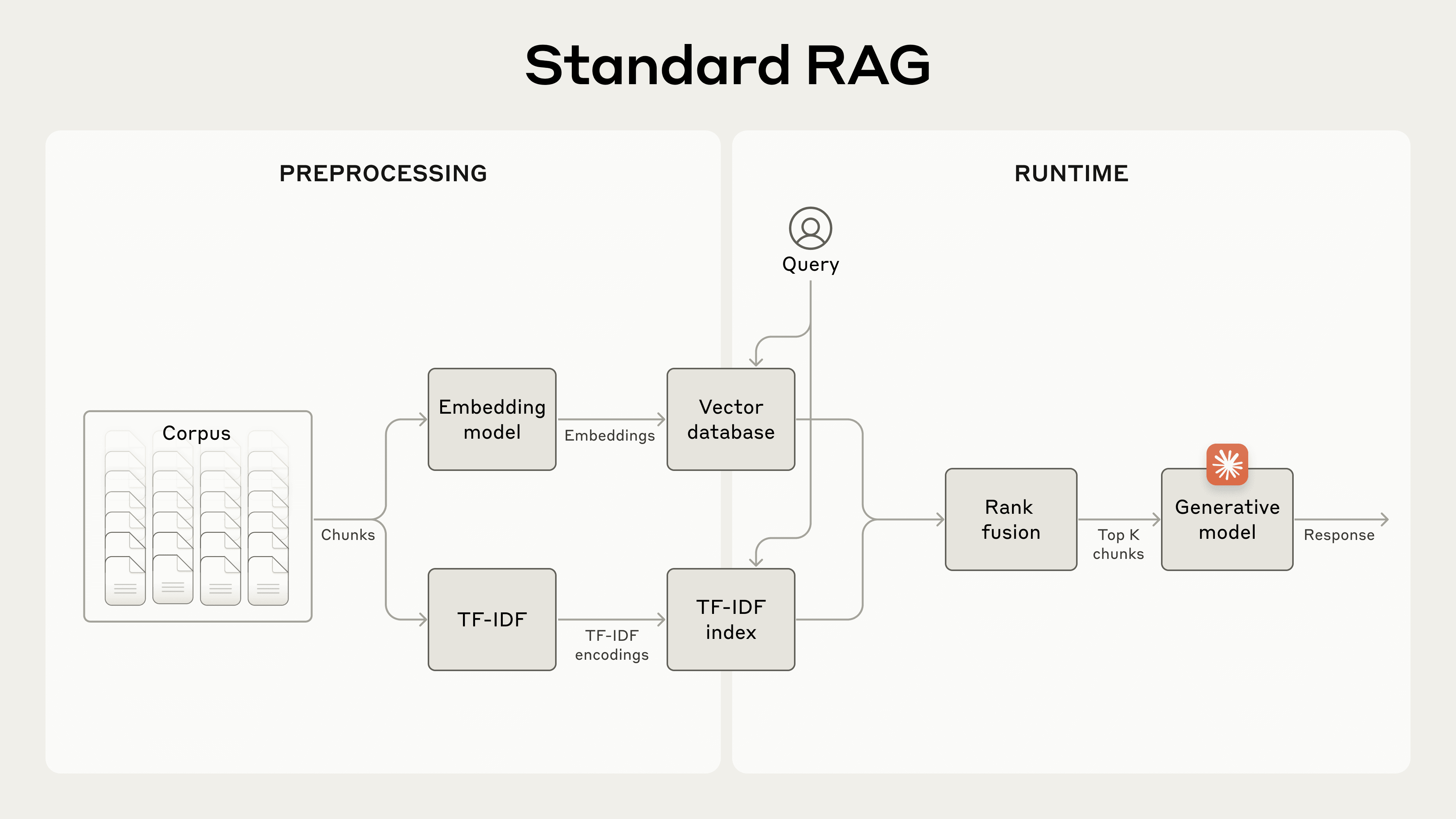
2. RAG 基础: 从向量检索到混合检索
3. 上下文丢失问题: SEC 填报案例
4. Contextual Retrieval 实现
5. 性能数据: 49% 检索失败率降低
6. Reranking: 进一步提升的叠加策略
7. 结论与实施建议
深度解读 苏格拉底式深度解读 →
这个 prompt 的设计有几个精妙之处:
- "short succinct" — 限制输出长度(50-100 tokens),避免上下文前缀本身变成新的噪声
- "situate this chunk within the overall document" — 明确目标是定位,不是总结或扩展
- "for the purposes of improving search retrieval" — 让模型知道上下文的用途是检索优化,不是信息补充
- 输入包含整个文档(
)+ 当前 chunk( — 模型能看到全局上下文)
成本控制: 使用 Claude 3 Haiku(而非 Opus/Sonnet)生成上下文,结合 Prompt Caching:
- 文档只加载一次到缓存
- 每个 chunk 只需传入 chunk 内容
- 实际成本: $1.02/百万文档 tokens — 极其低廉
与 JIT 策略的关系: 这是一种"预处理阶段的 JIT" — 在索引时(而非查询时)为每个 chunk 添加上下文。与 Effective Context Engineering 的 JIT 检索形成互补: 前者优化"找到什么",后者优化"用什么"。

这组数据揭示了 RAG 优化的一个核心原则: 不同技术解决不同类型的检索失败:
Contextual Embeddings 解决的失败:
- 语义相似但缺少上下文的 chunk
- 例: 查询 "Python 异步编程" 无法匹配到只说 "使用 async/await" 的 chunk
Contextual BM25 解决的失败:
- 包含关键专有名词但不在用户查询词汇表中的 chunk
- 例: 查询 "revenue growth" 无法匹配到只说 "3% increase over prior quarter" 的 chunk
叠加效应: 两种技术覆盖的失败模式有约 30% 重叠,但各自独占 70%。叠加后,覆盖的失败模式接近全集。
工程启示: 不要只依赖一种检索策略。混合检索(语义 + 关键词 + 上下文增强)在所有数据集上都优于单一方法。这是一个"免费午餐"式的优化。

Reranking 是第三层叠加优化:
Reranking 的工作原理:
- 初始检索取 top-150 chunks(宽松匹配,高召回率)
- Reranker 模型(如 Cohere)对每个 chunk 与查询的相关性打分
- 只保留 top-20 高分 chunks(精确排序,高精确率)
为什么 Reranking 能进一步提升: 初始检索(向量 + BM25)是"快速粗排",Reranking 是"慢速精排"。两者使用不同的相关性模型,互补性很强。
三层的完整收益链:
- 基线: 5.7% 失败率
- + Contextual Retrieval: 2.9%(降 49%)
- + Reranking: 1.9%(降 67%)
延迟/成本权衡: Reranking 增加约 100-200ms 延迟和额外 API 成本。文章建议根据场景权衡: 高价值查询(法律、医疗)值得 Reranking,实时聊天可能不需要。
Anthropic 在技术文章中坦诚推荐"最笨"方案,这种工程务实精神值得注意:
适用条件:
- 知识库 < 200K tokens(约 500 页)
- 使用 Prompt Caching 降低成本和延迟
- 检索准确率 = 100%(因为所有信息都在上下文中)
与 Contextual Retrieval 的关系: 这不是替代方案,而是不同规模的策略选择:
- < 200K tokens → 全文塞入(最简单、最准确)
- 200K-10M tokens → Contextual Retrieval(中等复杂度,高准确率)
- > 10M tokens → Contextual Retrieval + Reranking(最大规模)
这与 Effective Context Engineering 的核心思想完全一致: 选择匹配任务规模的策略,而非一味追求复杂方案。
关联 GitHub 项目
claude-cookbooks43500 stars代码实践建议
实现 Contextual Retrieval RAG 管道
用 Claude 为 chunk 生成上下文前缀,构建混合检索(embedding + BM25)管道
思维流程导图
flowchart TD A["Contextual Retrieval"] --> B["问题: RAG 检索不准"] A --> C["两大技术"] C --> C1["Contextual Embeddings
chunk 添加上下文后嵌入"] C --> C2["Contextual BM25
上下文增强关键词检索"] A --> D["流程"] D --> D1["文档分块"] D --> D2["Claude 为 chunk 添加上下文"] D --> D3["重新嵌入 + 索引"] D --> D4["混合检索"]
这个案例精确揭示了 RAG 的核心缺陷:
问题本质: 传统 RAG 的分块粒度(通常几百 tokens)在语义上是"原子"的,但原子化必然丢失"分子级"的上下文。
Contextual Retrieval 的解决方式:
为什么不是简单地用更大的 chunk: 大 chunk 解决了部分上下文问题,但引入新问题 — 嵌入粒度变粗,语义稀释。一个 2000 token 的 chunk 包含多个主题,嵌入向量无法精确代表任何一个。Contextual Retrieval 在保持细粒度的同时恢复了上下文。