1文章开篇对 Context Engineering 的定义
原文摘录
Context engineering is the delicate art and science of filling the context window with the right information for the next step.
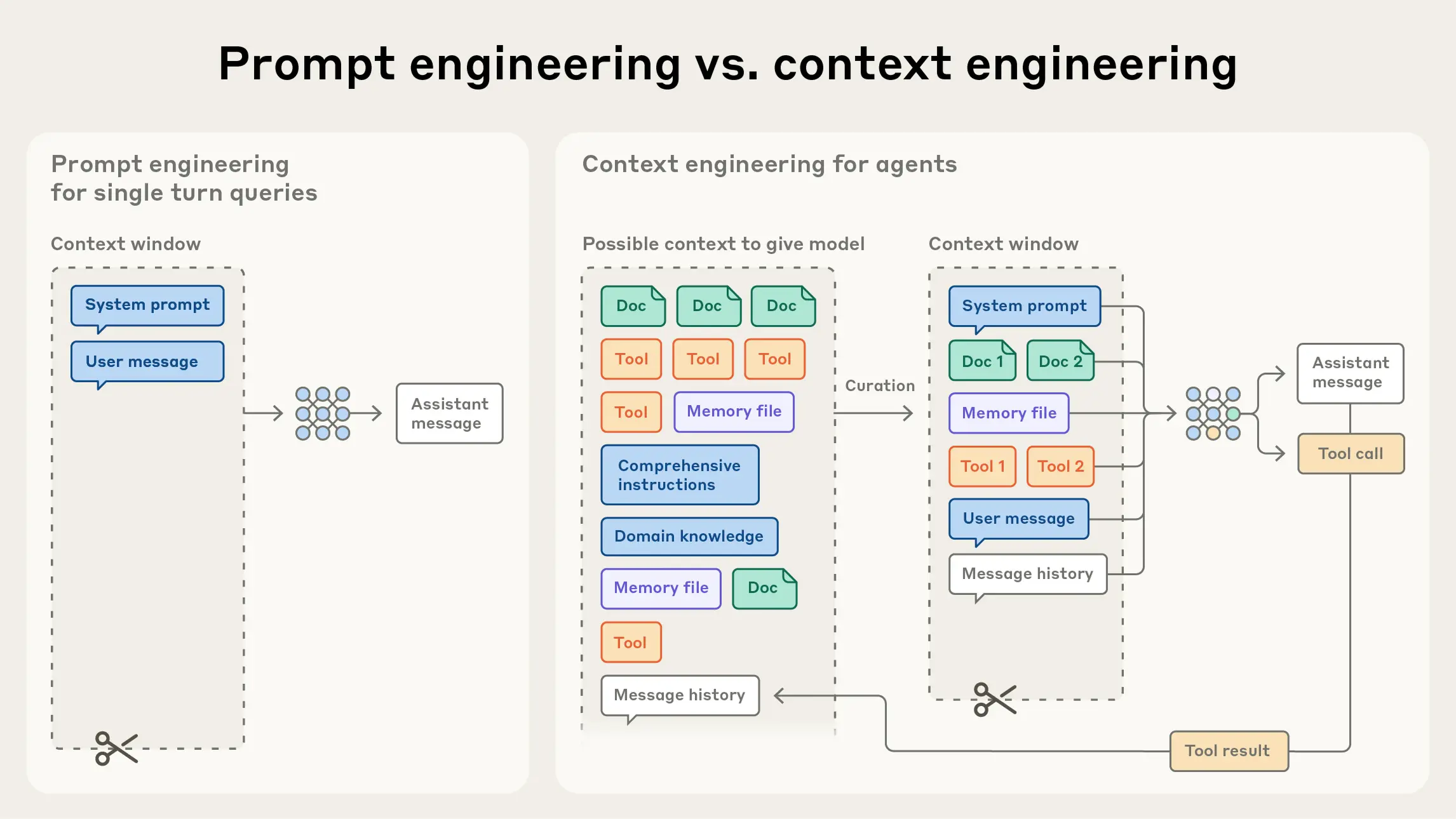
Prompt Engineering vs. Context Engineering — 从单次提示优化到全生命周期上下文管理
💡 类比理解
想象你是一位急诊室医生。面对一个病人,你不会把所有医学教科书、所有病人的病历都摊在桌上——你只需要当前症状、过敏史、最近的检查结果。Context Engineering 就是让 AI 像高效的急诊医生一样,在有限的工作台上只摆放当前决策需要的信息。
Prompt Engineering 不够用吗?我们一直在用它写 prompt 啊。
Prompt Engineering 关注的是如何措辞——像是在写一封措辞完美的信。但 Agent 不是一次性通信,而是一场持续数小时的项目会议。你需要管理的不是'一句话',而是'整个会议过程中的信息流'。Prompt Engineering 优化的是单次输入,Context Engineering 管理的是 Agent 整个生命周期的上下文状态。
等等,Agent 是'持续的项目会议'具体是什么意思?
想象一个 Agent 在重构代码:它先读取文件(第1步),分析架构(第2步),制定计划(第3步),逐步修改(第4-N步)。每一步需要不同的信息——第1步需要文件路径,第2步需要模块关系,第3步需要设计规范。Prompt Engineering 只优化了第1步的输入,Context Engineering 管理的是所有步骤的信息供给。
那 'art' 和 'science' 到底指什么?
'Science' 是可量化的:token 数量、注意力分布、响应延迟——你可以用 A/B 测试证明方案 A 比方案 B 好。'Art' 依赖经验判断:哪些信息对'下一步'有价值?这和烹饪一样——温度和时间是科学,但火候的拿捏是艺术。好的 Context Engineer 两手都要硬。
最后,为什么强调 'for the next step'?为所有场景准备信息不好吗?
这是最核心的洞察。大多数人试图为所有可能场景准备信息,但这导致上下文膨胀。转变思维:不是'Agent 可能需要什么',而是'Agent 的下一步需要什么'。下一步确定了,信息范围就自然缩小。这和丰田的 JIT 库存管理如出一辙——不囤积零件,需要时才调取。
但如果 Agent 的下一步不可预测呢?
那就需要两层保障:System Prompt 提供决策框架(告诉 Agent 如何选择下一步),加上工具集提供行动能力。有了框架,Agent 能在合理范围内自主决定;Context Engineering 的工作就是确保每一步都有充足但不过量的信息。下一节讲的 System Prompt 设计正是解决这个问题的。
📊 原理图解
flowchart LR
A["Agent 当前状态"] --> B{"判断下一步"}
B -->|"信息充足"| C["选择最小信息集"]
B -->|"信息不足"| D["调用工具检索"]
D --> C
C --> E["执行动作"]
E --> F["观察结果"]
F --> A
Context Engineering 核心循环: 每一步只为下一步准备最优信息集
GH
claude-code
Claude Code 的整个上下文管理架构是本文的最佳实践范本
2关于上下文成本的核心论述
原文摘录
Adding context is not free. Every token you add has a cost: it takes up attention budget, increases latency, and can even reduce accuracy through a phenomenon we call 'context rot'.
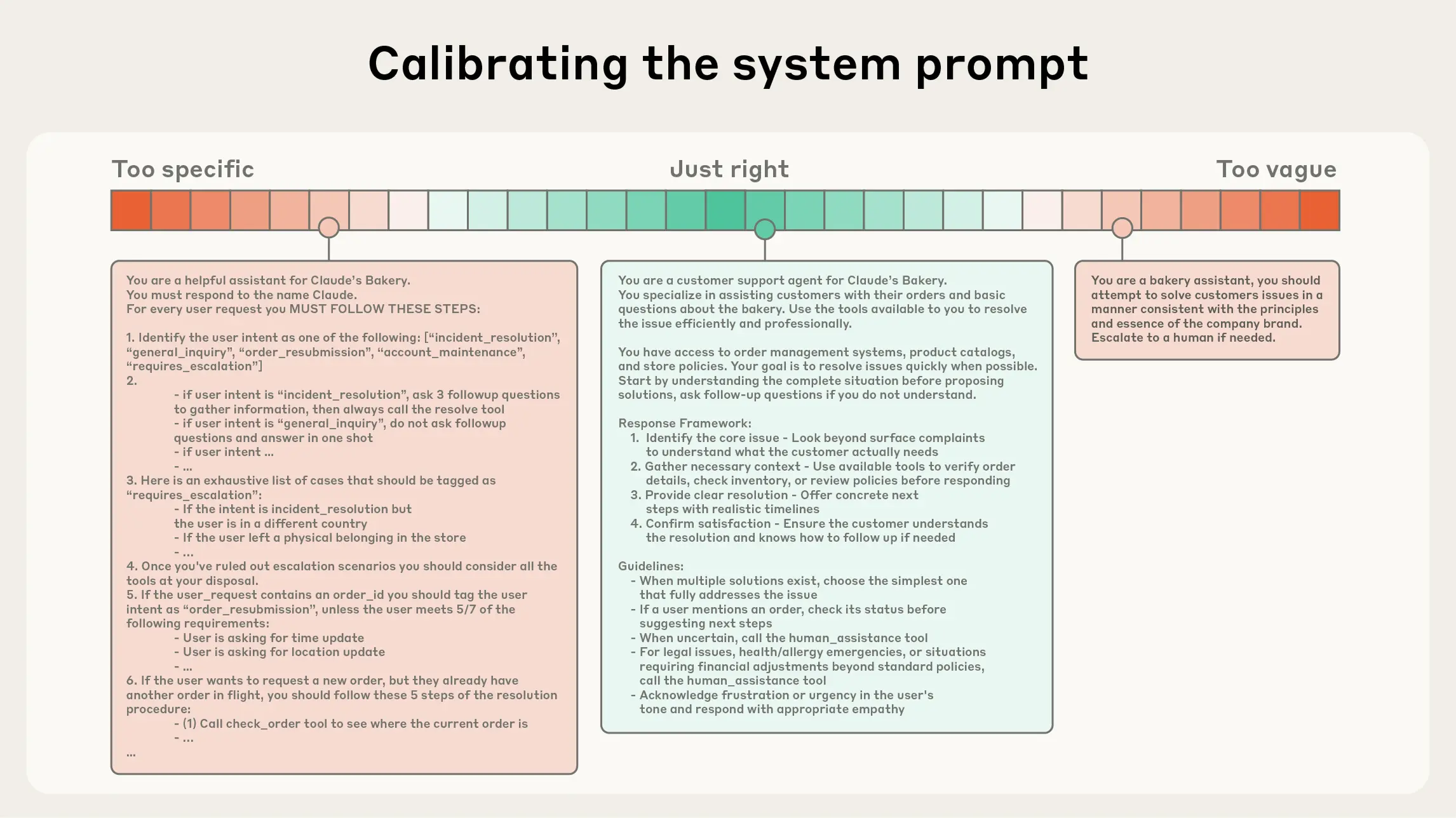
System Prompt Calibration — 系统提示词的'正确高度'平衡
💡 类比理解
想象一间教室里有一位老师。如果教室里有 5 个学生在讨论,老师能准确回答每个人的问题。但如果教室里同时有 100 个人在说话——有人在聊天气、有人在念菜单、有人在读报纸——老师反而连最近的一个问题都听不清了。这就是 Context Rot:不是信息太少,而是信噪比太低。
为什么更多的上下文反而会让模型表现变差?模型不是上下文窗口越大越好吗?
关键在于注意力机制。Transformer 模型的注意力是 N^2 复杂度——每增加一个 token,它需要和所有已有 token 计算相关性。当上下文中有大量低价值信息时,模型的注意力被分散到无关内容上,就像在 100 人嘈杂的房间里,老师把注意力平均分给了每个人。
那为什么不直接过滤掉低价值信息?
因为'低价值'是动态的。同一个信息在这一步可能没用,在下一步可能至关重要。问题不是'过滤什么',而是'什么时候加载什么'。这正是 JIT(Just-in-Time)策略的核心——不在启动时加载所有信息,而是在需要时才检索。
Context Rot 有具体的量化指标吗?
有。Anthropic 内部测试发现:上下文填充率低于 30% 时,推理准确率基本不受影响;30%-70% 之间开始缓慢下降;超过 70% 后准确率显著跳水。这个 70% 阈值就是 Context Rot 的临界点。实际操作中,应该把上下文填充率控制在 50% 以下,留出足够的'注意力余量'。
那如果我确实需要很多信息怎么办?
文章提出了三种长程策略:Compaction(压缩历史对话)、Structured Notes(Agent 主动写笔记)、Sub-agent(将工作分发到隔离上下文)。这三种策略的组合可以让你在理论上处理无限长的任务,同时保持每一步的上下文都在'安全区'内。后面我们会逐一深入。
📊 原理图解
flowchart LR
A["0-30% 填充"] -->|"高信噪比"| B["准确率正常"]
C["30-70% 填充"] -->|"信噪比下降"| D["准确率缓慢下降"]
E["70%+ 填充"] -->|"Context Rot"| F["准确率显著跳水"]
style A fill:#BBF7D0
style B fill:#BBF7D0
style C fill:#FDE68A
style D fill:#FDE68A
style E fill:#FCA5A5
style F fill:#FCA5A5
Context Rot 效应: 上下文填充率与推理准确率的关系
GH
claude-code
Claude Code 的 Compaction 功能正是解决 Context Rot 的核心机制
3System Prompt 设计的'正确高度'原则
原文摘录
The best system prompts live at the right altitude — specific enough to be useful, but not so specific that they break when the real world inevitably diverges from your expectations.
💡 类比理解
System Prompt 就像给新员工的入职手册。写得太空泛('做一个好员工'),新人不知道该做什么;写得太空细('当客户说 A 你必须回复 B'),新人遇到手册没覆盖的情况就手足无措。最好的手册告诉你公司的价值观和决策原则,让你在遇到新情况时也能做出合理判断。
为什么不能把所有规则都写进 System Prompt?规则越完整不是越好吗?
两个原因。第一,Token 成本:System Prompt 在每次 API 调用中都会发送,100 条规则可能占用 20K tokens。第二,冲突爆炸:当规则数量增长,规则之间的矛盾会指数级增加。'当用户要求 X 时执行 Y' 和 '当系统状态为 Z 时不能执行 Y'——这两条在 X+Z 同时出现时就矛盾了。
那怎么判断 System Prompt 写在'正确高度'?
问自己一个问题:'这条指令在 80% 的场景下都有用吗?'如果是,它属于 System Prompt。如果只在特定场景有用,它应该作为工具描述、RAG 检索结果、或 JIT 加载的知识。Claude Code 的 CLAUDE.md 只包含项目级编码规范——这些规范在任何代码修改场景下都适用。
XML 和 Markdown 分区策略是什么?
当 System Prompt 内容较多时,用结构化标记分区。比如用
... 包裹编码规范,用
... 包裹架构决策。这让模型能
快速定位相关信息,而不是在整段文字中搜索。这就像给文档加目录——内容没变,但检索效率大幅提升。
📊 原理图解
flowchart TD
A["System Prompt 设计"] --> B{"信息层级判断"}
B -->|"80%+ 场景通用"| C["System Prompt 常驻"]
B -->|"特定场景才用"| D["工具描述 / RAG / JIT"]
C --> E["XML/Markdown 分区"]
E --> F["决策框架 + 原则"]
D --> G["运行时按需加载"]
System Prompt 的'正确高度': 区分常驻原则和按需加载知识
GH
claude-code
CLAUDE.md
Claude Code 的 CLAUDE.md 是'正确高度'原则的典型实践
4Just-in-Time 上下文检索策略
原文摘录
Instead of loading all potentially relevant information upfront, the agent maintains lightweight reference identifiers and loads the actual data on demand.
💡 类比理解
JIT 策略就像图书馆 vs 自己的书房。旧方式是把所有书都搬进书房——书房很快就满了,而且 90% 的书你暂时不看。JIT 方式是只在书房放一张图书目录,需要哪本书时再去书架上取。目录占一面墙,书架有无限空间。Claude Code 就是这个'图书馆模式':glob 是目录,grep/read 是取书。
JIT 和预加载的最大区别是什么?
核心区别在于'索引'和'内容'的分离。预加载把所有内容都放进上下文——假设'信息越多决策越好'。JIT 只放索引(文件路径、模块名、函数签名),内容在需要时才通过工具加载。索引通常只有几百 tokens,而全部内容可能有几十万 tokens。
这个'索引和内容分离'在计算机科学里有对应概念吗?
完美对应操作系统的虚拟内存。页表(Page Table)常驻内存——它记录每个虚拟页面对应的物理位置。实际的数据页面按需从磁盘换入。页表很小(几十 KB),但管理的地址空间可以有几个 GB。JIT 策略也一样:索引常驻上下文,管理的是整个知识库的'地址空间'。
Claude Code 的 glob + grep + read 是怎么实现 JIT 的?
三步组合拳:glob 扫描目录结构(获得文件列表 = 索引)→ grep 搜索关键词(缩小范围 = 定位页面)→ read 读取具体文件(加载内容 = 换入页面)。每一步的输出都是下一步的输入,而且每一步只消耗极少 tokens。一个 10 万行代码库,glob 只要 200 tokens 就能建立完整索引。
📊 原理图解
flowchart LR
subgraph "上下文窗口 常驻"
A["文件索引 200 tokens"]
end
subgraph "运行时按需加载"
B["glob 扫描"]
C["grep 搜索"]
D["read 读取"]
end
A --> B --> C --> D
D -->|"关键代码 500 tokens"| E["推理决策"]
JIT 检索: 索引常驻 200 tokens,按需加载关键内容
GH
claude-code
Claude Code 的 glob/grep/read 三件套是 JIT 策略的标杆实现
5三种长程上下文策略之 Compaction
原文摘录
Compaction works by summarizing the conversation history when it gets too long, preserving the key decisions and context while dropping the back-and-forth details.
💡 类比理解
Compaction 就像项目经理的周报。一周内有 50 封邮件、10 次会议、无数次讨论,但周报只需要 3 段话:做了什么决策、当前进度、下周计划。新接手的同事看周报就能继续推进,不需要阅读全部邮件。Compaction 就是让 Agent 每隔一段时间写一次'周报',用摘要替代原始对话。
Compaction 的触发时机是什么?等到上下文满了再压缩吗?
不是等到完全满,而是接近阈值时触发。Claude Code 的策略是在上下文使用量达到约 70-80%时启动压缩。这和 Context Rot 的 70% 临界点呼应——在准确率跳水之前就完成压缩,确保 Agent 始终在'安全区'内工作。
压缩过程会不会丢失关键信息?
关键在于区分'过程'和'状态'。过程信息('我尝试了方案 A,不行,又试了方案 B,也不行,最后方案 C 成功了')大部分可以丢弃。状态信息('最终选择了方案 C,原因是 X')必须保留。Claude Code 让 Claude 自己判断哪些是状态——让模型总结自己的对话,效果比人工规则好得多。
用 AI 来压缩 AI 的对话?这不会有信息失真吗?
这正是'art'的部分。失真是不可避免的,但可控的失真优于不可控的 Context Rot。一次精心设计的压缩可能丢失 5% 的细节,但 Context Rot 在 70% 填充率后每增加 10% 就丢失更多推理能力。两害相权取其轻——而且压缩后的摘要可以随时通过 JIT 检索补充细节。
📊 原理图解
flowchart TD
A["对话历史增长"] --> B{"上下文 > 70%?"}
B -->|"否"| A
B -->|"是"| C["触发 Compaction"]
C --> D["模型总结对话"]
D --> E["保留: 决策+状态+里程碑"]
D --> F["丢弃: 尝试过程+已撤销方案"]
E --> G["压缩摘要"]
G --> H["继续工作"]
Compaction 流程: 在 Context Rot 临界点前压缩对话历史
GH
claude-code
src/compaction
Claude Code 的 Compaction 实现——用 Claude 自身来总结对话历史
6Sub-agent 架构的分发策略
原文摘录
Sub-agents allow you to isolate work into separate context windows. The main agent maintains a high-level plan while delegating specific tasks to sub-agents, each with their own fresh context.
💡 类比理解
Sub-agent 就像建筑公司的项目经理。项目经理(主 Agent)拿着总设计图纸,但不亲自砌墙。他把'水电'分给电工组,'泥瓦'分给泥瓦组,'木工'分给木工组。每组有自己独立的工作台和工具箱(独立 context window),互不干扰。每组完成后只交回验收报告(结构化结果),而不是把整栋材料都搬回项目经理办公室。
Sub-agent 和 Compaction 有什么本质区别?
Compaction 是在同一间房间里做空间整理——把旧材料打包压缩,腾出新空间。Sub-agent 是另外开一间新房间。Compaction 适合线性任务(一件事做完做下一件),Sub-agent 适合可并行的任务(同时做几件独立的事)。两者可以叠加:子 Agent 内部也可以做 Compaction。
主 Agent 和子 Agent 之间怎么传递信息?
关键原则是'结果而非过程'。子 Agent 执行完毕后,只返回结构化的结果摘要——比如'模块 A 的测试覆盖率从 60% 提升到 90%',而不是返回 500 行的对话历史。这就像建筑公司交回的是'验收报告'而不是'施工日志'。主 Agent 只需要结果来做后续决策。
什么时候该用 Sub-agent 而不是在一个 Agent 里顺序执行?
三个信号:1. 子任务之间信息交换有限(不需要共享大量中间状态);2. 子任务可以并行执行(不互相依赖);3. 每个子任务需要不同的工具集或知识。如果三个条件都满足,Sub-agent 可以同时提升效率和上下文利用率。如果子任务之间紧密耦合,顺序执行 + Compaction 更合适。
📊 原理图解
flowchart TD
A["主 Agent
全局计划 + 状态"] --> B["子 Agent A
独立上下文"]
A --> C["子 Agent B
独立上下文"]
A --> D["子 Agent C
独立上下文"]
B -->|"结构化结果"| E["主 Agent 整合"]
C -->|"结构化结果"| E
D -->|"结构化结果"| E
E --> F["继续推进"]
style A fill:#E3DACC
style B fill:#FFF5E8
style C fill:#FFF5E8
style D fill:#FFF5E8
Sub-agent 架构: 主 Agent 分发任务,子 Agent 独立执行后返回结构化结果
GH
claude-code
Claude Code 使用 Sub-agent 隔离复杂任务的上下文