Building Effective AI Agents
苏格拉底式深度解读
解读目录
1. 核心设计哲学: 简单优先 2. Agent vs Workflow 的精确定义 3. Orchestrator-Workers 模式详解 4. ACI 概念的提出 5. Evaluator-Optimizer 模式的适用条件1核心设计哲学: 简单优先
原文摘录
When building applications with LLMs, we recommend finding the simplest solution possible and only adding complexity when needed.
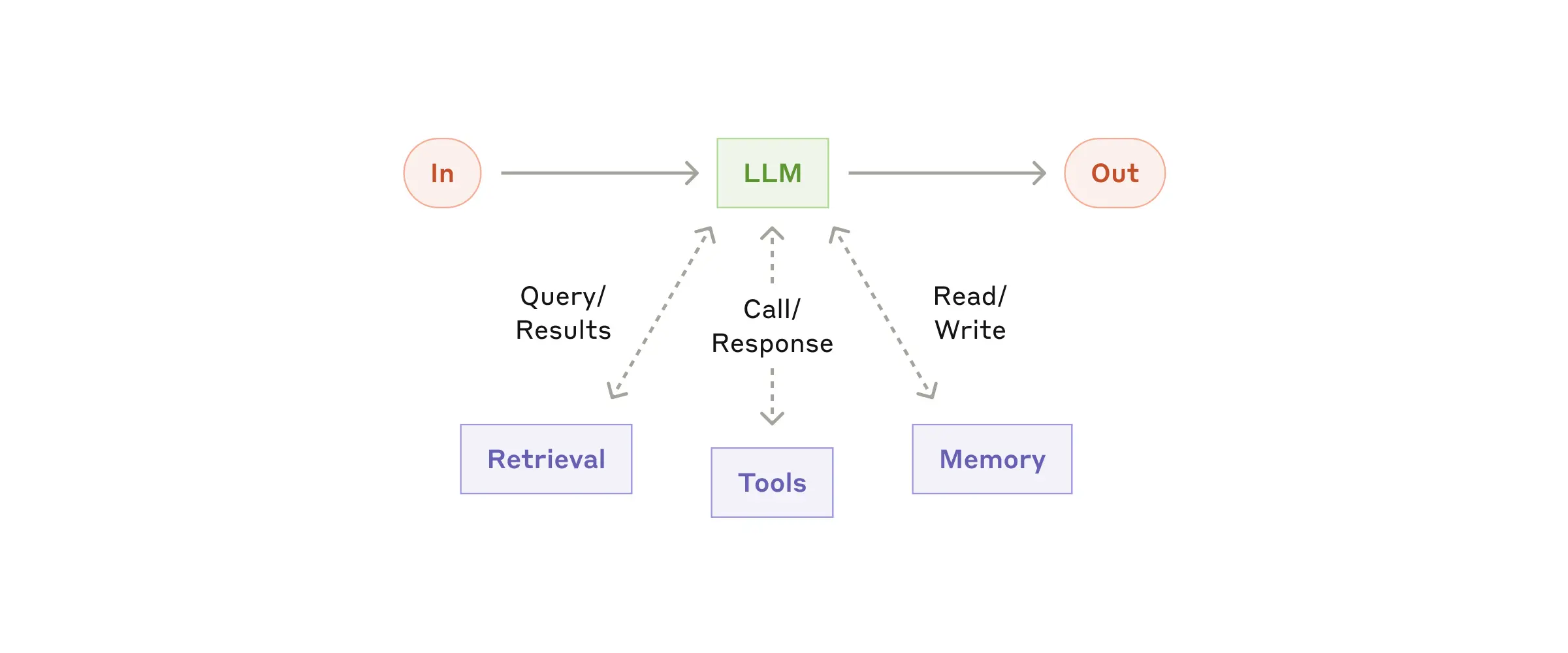
Augmented LLM — 增强型 LLM 架构: 模型 + 工具 + 检索
💡 类比理解
就像装修房子: 你不会一上来就请一个"全能装修队"把所有房间同时开刀。先刷一面墙试试效果,确认颜色满意再扩展到整个房间,最后才考虑是否需要请设计师做整体规划。每一步都是在"证明需要"之后才增加投入。
为什么文章建议从最简单的方案开始?直接用一个强大的 Agent 框架不好吗?
因为复杂度是有成本的。每个额外的层级——工具调用、循环逻辑、错误恢复——都增加调试难度和出错概率。一个单次 LLM 调用 5 分钟就能验证想法,而搭建 Agent 框架可能需要数天,最终发现根本不需要。
那我怎么判断什么时候该从单次调用升级到 Workflow?
关键看两个信号: 准确率瓶颈和步骤间的依赖关系。如果单次调用的准确率稳定在某个阈值以下,且任务天然可以拆成有先后顺序的子步骤,那 Prompt Chaining 就是自然的下一步。
在实际项目中,这条'复杂度递增路径'最常见的反模式是什么?
最常见的反模式是框架先行——还没验证核心价值,就引入 LangGraph/CrewAI 等框架,把 80% 的精力花在框架配置上,而不是 prompt 调优。正确做法是先用手写代码验证单次调用效果,再逐步引入结构。
📊 原理图解
flowchart LR A["单次 LLM 调用
起步方案"] -->|"准确率不足"| B["Prompt Chaining
串行多步"] B -->|"需要分类处理"| C["Routing
分类路由"] B -->|"任务可拆分"| D["Parallelization
并行执行"] C -->|"分解方式不确定"| E["Orchestrator-Workers
动态编排"] D -->|"分解方式不确定"| E B -->|"质量需迭代"| F["Evaluator-Optimizer
迭代优化"] E -->|"路径不可预测"| G["自主 Agent"] style A fill:#d4edda style G fill:#f8d7da
复杂度递增路径图 — 从最简单的单次 LLM 调用开始,按需升级到更复杂的模式
claude-cookbooks
misc/patterns/prompt_chaining.ipynb
包含从简单到复杂的 5 种 Workflow 模式的完整代码示例,可直接对照学习复杂度递增路径
claude-agent-sdk-python
官方 Python SDK 提供了从单次调用到多 Agent 协作的渐进式构建工具
2Agent vs Workflow 的精确定义
原文摘录
An agent can be defined as a system that uses an LLM to decide the flow of the application. Unlike workflows, agents are not constrained to follow a predetermined path.
💡 类比理解
Workflow 像是地铁线路图——每个站点、每条线路都是预先规划好的,乘客只需选择正确的线路就能到达目的地。Agent 则像是出租车——乘客只说出目的地,司机根据实时路况自主选择路线,可能走不同的路到达同一个地方。地铁线路图更可靠但缺乏弹性,出租车更灵活但你不能完全预测它走哪条路。
Workflow 和 Agent 最本质的区别是什么?
最本质的区别在于谁做决策。Workflow 中,代码(开发者写的逻辑)决定下一步做什么;Agent 中,LLM 自己决定下一步做什么。一个是'人编排好的流水线',一个是'AI 自主导航'。
既然 Agent 更灵活,为什么不全用 Agent?
因为灵活性是有代价的。非确定性意味着不可预测。Agent 可能在同一任务上每次走不同路径,这让调试、测试和成本控制都变得困难。如果你的任务路径可以预先定义好,Workflow 的可靠性和可控性远优于 Agent。
在实际项目中,如何处理 Workflow 和 Agent 的边界情况——比如大部分路径可预定义,但偶尔需要 LLM 自主决策?
常见做法是混合架构——主框架用 Workflow 定义确定性路径,在特定节点嵌入 Agent 处理不确定的子任务。例如代码审查流程: 主体是 Workflow(格式检查 → 静态分析 → 安全扫描),但在安全扫描环节发现异常时,启动一个 Agent 深入调查具体风险,Agent 的结论再回到 Workflow 的下一个节点。
📊 原理图解
flowchart TD
subgraph "Workflow(确定性路径)"
W1["输入"] --> W2["分类 LLM"]
W2 -->|"类型A"| W3["处理 A"]
W2 -->|"类型B"| W4["处理 B"]
W3 --> W5["格式化输出"]
W4 --> W5
end
subgraph "Agent(非确定性路径)"
A1["目标"] --> A2["LLM 思考"]
A2 --> A3{"下一步?"}
A3 -->|"搜索"| A4["工具: 搜索"]
A3 -->|"分析"| A5["工具: 代码分析"]
A3 -->|"已完成"| A6["输出结果"]
A4 --> A2
A5 --> A2
end
style W2 fill:#cce5ff
style A3 fill:#fff3cd
Workflow vs Agent 路径对比 — Workflow 的分支由代码决定,Agent 的分支由 LLM 实时决定
claude-code
Claude Code 是典型的 Agent 实现——LLM 自主决定何时搜索、编辑、运行命令,而非按预定义路径执行
claude-cookbooks
misc/patterns
对比同一任务分别用 Workflow 和 Agent 实现的示例代码,帮助理解二者边界
3Orchestrator-Workers 模式详解
原文摘录
In an orchestrator-workers workflow, a central LLM dynamically breaks down tasks and delegates them to worker LLMs, then synthesizes their results.
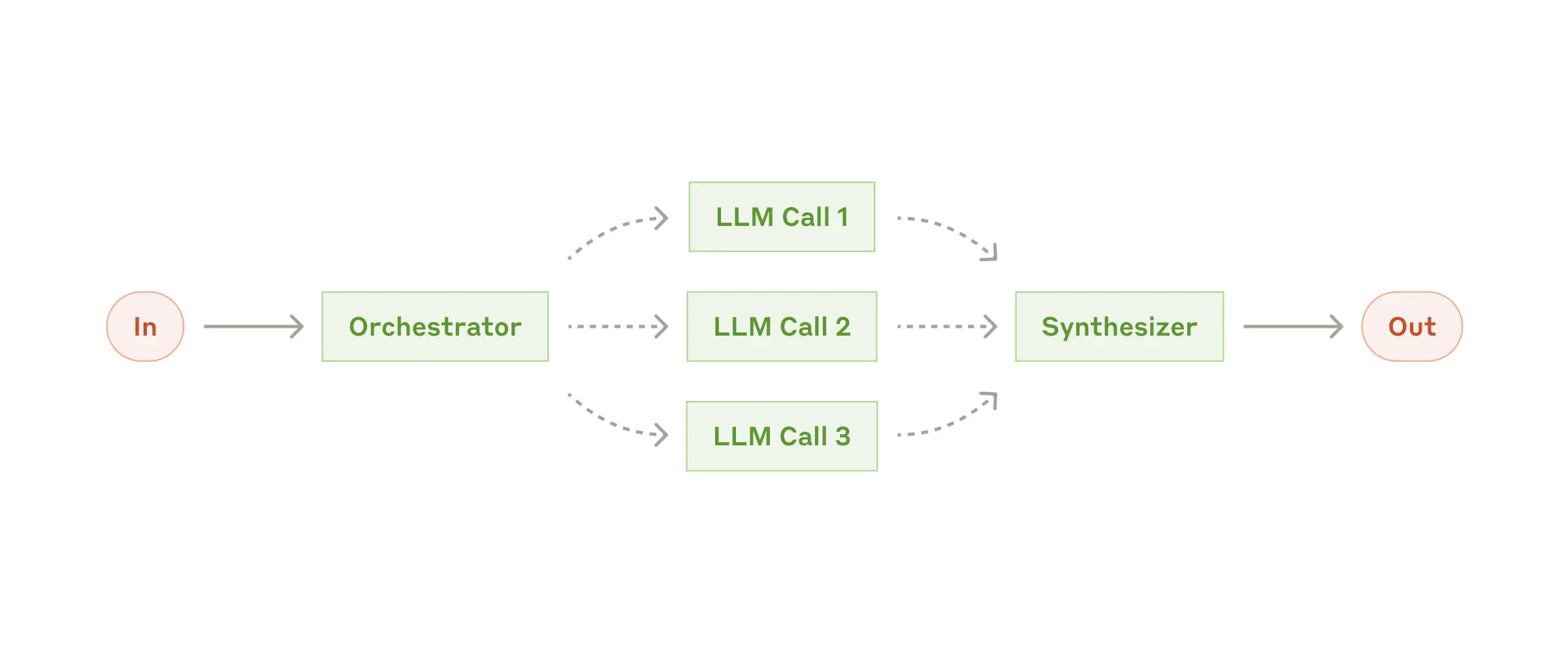
Orchestrator-Workers — 动态分解任务并分发给 Worker
💡 类比理解
就像一个建筑项目经理(Orchestrator)和一群专业工人(Workers)的关系。项目经理拿到一份建筑蓝图后,根据实际情况动态决定需要几个电工、几个水管工、几个油漆工,然后分派任务。他不是机械地把同一件事做 N 遍,而是根据每个子问题的性质分配最合适的工人。最后项目经理汇总所有工人的汇报,形成完整的工程报告。
Orchestrator-Workers 和普通的并行处理有什么区别?
核心区别在于分解策略是动态的。普通并行处理是预先知道要做什么,比如翻译 5 种语言。Orchestrator-Workers 是拿到任务后才决定怎么拆、拆成几个、每个子任务是什么。它是'看完题再解题'而不是'按模板填空'。
Orchestrator 怎么决定把任务拆成几份?它自己也是 LLM,会不会拆得不好?
这正是设计的难点。Orchestrator 的 prompt 中必须包含分解指导原则,比如'按模块边界拆分,每个子任务不超过 500 行代码范围'。同时要设置合理的下限和上限——最少拆 2 个、最多拆 10 个子任务,防止拆得过粗或过细。实践中,给 Orchestrator 看几个分解示例(few-shot)能显著提升拆分质量。
当 Worker 们的结论互相矛盾时,Orchestrator 该怎么处理?有没有工程上的最佳实践?
有三种常见策略: 1) 加权投票——给每个 Worker 的结论附上置信度,加权汇总;2) 再验证——Orchestrator 针对矛盾点发起第三轮专项检查,让新 Worker 专门裁决争议;3) 保守优先——在安全敏感场景下,有风险就采纳风险结论(宁可误报不漏报)。关键是 Orchestrator 的汇总 prompt 中要明确指出矛盾存在,而非隐式处理。
📊 原理图解
sequenceDiagram participant U as 用户请求 participant O as Orchestrator participant W1 as Worker 1 participant W2 as Worker 2 participant W3 as Worker 3 U->>O: 提交复杂任务 activate O O->>O: 分析任务,动态决定分解方式 O->>W1: 子任务 A(如: 前端模块检查) activate W1 O->>W2: 子任务 B(如: 后端 API 检查) activate W2 O->>W3: 子任务 C(如: 数据库影响检查) activate W3 W1-->>O: 返回结果 A deactivate W1 W2-->>O: 返回结果 B deactivate W2 W3-->>O: 返回结果 C deactivate W3 O->>O: 汇总结果,处理矛盾 O-->>U: 综合报告 deactivate O
Orchestrator-Workers 序列图 — Orchestrator 动态分解任务、分发 Worker、汇总结果
claude-code
Claude Code 在处理大型代码库变更时,内部采用类似 Orchestrator-Workers 模式动态分配子任务
claude-agent-sdk-python
examples/orchestration
SDK 中提供了 Orchestrator-Workers 模式的参考实现,包含任务分解和结果汇总的完整逻辑
4ACI 概念的提出
原文摘录
The design of tool interfaces — the Agent-Computer Interface (ACI) — deserves as much attention as the Human-Computer Interface (HCI).
💡 类比理解
就像给一位外国实习生写工作手册。你不能假设他能"意会"任何操作,每个按钮叫什么、点了之后会发生什么、出错时屏幕上会显示什么——都要写得清清楚楚。LLM 就是那个"外国实习生",它对工具的理解完全来自你写的工具定义。一份好的工作手册能让实习生第二天就上手,一份差的手册会让他天天问问题还频繁出错。
ACI 是什么意思?为什么要专门为 LLM 设计工具接口?
ACI 全称 Agent-Computer Interface,类比 HCI(人机交互界面)。之所以需要专门设计,是因为 LLM 调用工具的方式和人类完全不同——它只能通过文本描述来理解工具的用途、参数含义和返回值格式。一个对人类很直观的工具(比如一个搜索框),如果没给 LLM 足够的文字说明,它根本不知道怎么用。
具体来说,一个'好的'工具接口应该长什么样?能举个例子吗?
以文件搜索工具为例。差的接口: 名字叫
sf,参数是 q,返回自由文本。好的接口: 名字叫 search_files,参数有清晰的 JSON Schema(query: string + 描述说明支持通配符),返回结构化的 JSON(包含文件路径、匹配行号、上下文片段)。两者的功能完全一样,但后者让 LLM 的调用准确率提升数倍。当 Agent 在循环中反复调用工具时,工具接口设计不好会有什么连锁反应?
会引发错误放大效应。第一轮如果 LLM 选错工具或传错参数,返回的错误信息又不清楚,LLM 就会基于错误的理解尝试'修复',结果越改越偏。更严重的是token 浪费——每一轮错误调用都消耗 token,而 Agent 可能陷入 5-10 轮的无效循环。实践中,优化工具接口后,平均循环轮次可以从 4.2 轮降到 1.8 轮。
📊 原理图解
flowchart LR
subgraph "差的 ACI"
B1["工具名: sf"] --> B2["参数: q (无描述)"]
B2 --> B3["返回: 自由文本"]
B3 --> B4["LLM: 困惑,反复试错"]
end
subgraph "好的 ACI"
G1["工具名: search_files"] --> G2["参数: query (支持通配符)
+ scope (搜索范围)"]
G2 --> G3["返回: 结构化 JSON
{path, line, context}"]
G3 --> G4["LLM: 一次调用成功"]
end
style B4 fill:#f8d7da
style G4 fill:#d4edda
差的 ACI vs 好的 ACI 对比 — 工具接口设计直接影响 LLM 调用效率和准确率
claude-code
Claude Code 的工具接口(文件操作、搜索、终端命令)是 ACI 设计的优秀实践案例,每个工具都有详细的描述和结构化的参数定义
claude-cookbooks
tool_use
包含工具接口设计的最佳实践示例,对比好/坏工具定义对 LLM 行为的影响
5Evaluator-Optimizer 模式的适用条件
原文摘录
The evaluator-optimizer workflow is particularly effective when we have clear evaluation criteria and when iterative refinement provides measurable value.
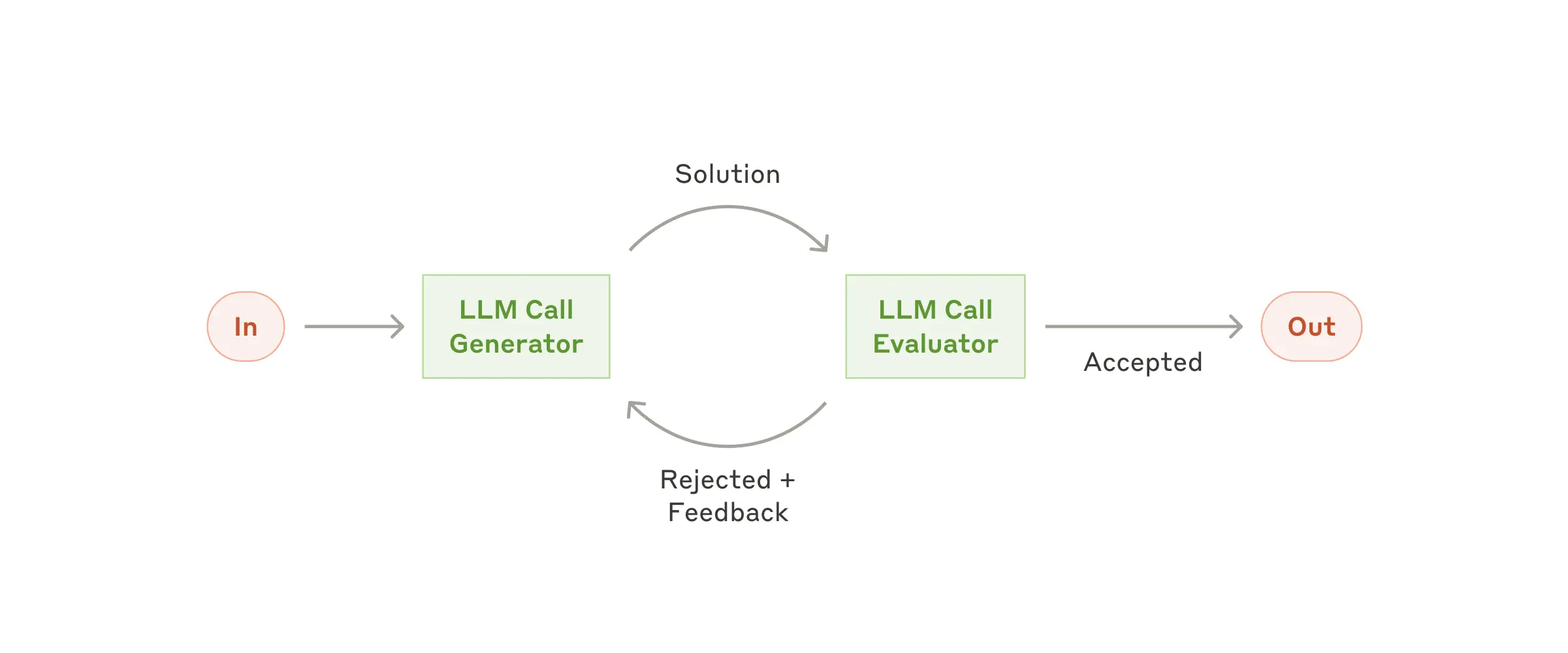
Evaluator-Optimizer — 迭代评估与持续优化循环
💡 类比理解
就像论文的"写-审"循环: 作者提交初稿,审稿人给出具体的修改意见(不是简单说"写得不好",而是指出"第三段的论证逻辑缺失"),作者针对意见修改后重新提交,直到审稿人满意为止。关键是审稿标准必须明确——如果审稿人说"感觉不够好",作者就不知道该改哪里。
Evaluator-Optimizer 模式是怎么工作的?
它是一个'生成-评审-修改'的循环。一个 LLM(Generator)负责生成内容,另一个 LLM(Evaluator)负责对照标准评估并给出具体反馈。如果没通过,Generator 根据反馈修改后重新提交,循环直到 Evaluator 认为合格。
为什么需要两个 LLM?用一个 LLM 自己检查自己不行吗?
自评的问题是盲区重叠——生成时犯的错误,自评时往往也看不出来。两个独立的 LLM 更像'交叉审查',Evaluator 没有生成者的思维惯性,更容易发现逻辑漏洞和遗漏。不过在一些轻量场景下,同一个 LLM 搭配不同的 system prompt(一个角色负责生成、一个角色负责评审)也能取得不错效果。
怎么避免这个循环无限进行下去——Generator 和 Evaluator 始终无法达成一致?
三个关键工程措施: 1) 设置最大迭代次数(通常 3-5 轮),超过则强制输出当前最优版本;2) 量化评估标准——Evaluator 的输出必须是结构化的评分(如各维度 1-5 分),而非模糊的'通过/不通过';3) 收敛检测——如果连续两轮评分差异小于阈值(如 0.1 分),说明已接近天花板,提前终止。
📊 原理图解
flowchart TD G1["Generator
生成初始输出"] --> E1["Evaluator
对照标准评估"] E1 --> D{"通过评估?"} D -->|"是"| F["输出最终结果"] D -->|"否"| R["Evaluator 生成
具体反馈"] R --> G2["Generator
根据反馈修改"] G2 --> E2["Evaluator
重新评估"] E2 --> D2{"通过 / 超过轮次?"} D2 -->|"通过"| F D2 -->|"未通过但
未超限"| G2 D2 -->|"超过最大轮次"| F2["输出当前
最优版本"] style F fill:#d4edda style F2 fill:#fff3cd
Evaluator-Optimizer 迭代循环图 — 生成与评估交替进行,直到通过标准或超过最大轮次
claude-cookbooks
包含 Evaluator-Optimizer 模式的代码示例,展示了代码生成 + 自动审查的迭代循环
claude-agent-sdk-python
examples/evaluator_optimizer
SDK 中提供的 Evaluator-Optimizer 参考实现,包含收敛检测和最大轮次控制